Identify failures on critical terms (e.g., medical vocabulary)
Compare models, configurations, and prompts reliably
Debug systematic errors and improve product quality
A Better Way to Evaluate ASR
Metrics like Word Error Rate (WER) treat all words equally — but in real-world use cases, not all errors carry the same weight. Missing filler words is very different from missing a diagnosis, medication, or key symptom. ErrorAlign is a next-generation alignment method designed for modern speech recognition. Instead of forcing transcripts into rigid, one-to-one comparisons, it produces more natural, human-like mappings between reference and model output — making error analysis clearer, more reliable, and more actionable.Click here to learn about Error Align
Produces more human-like transcript comparisons
Improves error attribution
Enables deeper, more actionable analysis
Improves error attribution
Enables deeper, more actionable analysis
Use Corti Canal to Analyze for you
To make this practical, we’ve open-sourced Corti Canal, a tool for evaluating ASR outputs using Error Align. Don’t spend your time on figuring out how to evaluate and jump right into evaluation.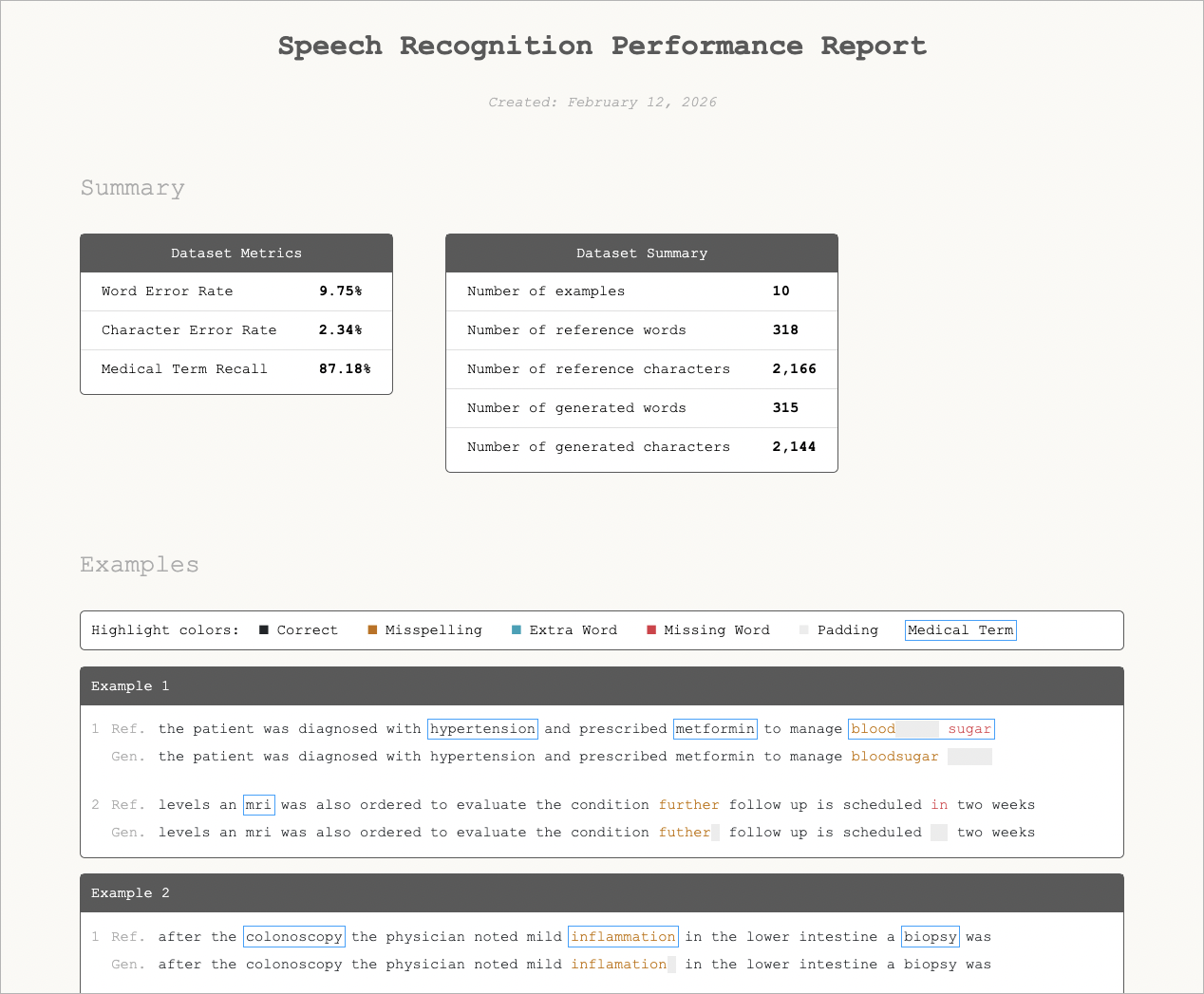
Click here to Install Corti Canal
Built-in normalization
Advanced alignment methods
Visual error analysis
Domain-specific metrics (e.g., medical term recall)
Advanced alignment methods
Visual error analysis
Domain-specific metrics (e.g., medical term recall)
What This Enables
Instead of asking:“What’s my WER?”You can answer:
“Where is my model failing — and does it matter?”
For best results, evaluate using normalized text, advanced alignment, and domain-specific metrics.