> ## Documentation Index
> Fetch the complete documentation index at: https://docs.corti.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Speech-to-Text Performance Evaluation
> Learn how to quantify and visualize speech recognition results
Building with speech-to-text doesn’t stop at transcription. You need to understand how well your system performs in real-world conditions; however, evaluations can be complex with varying methodologies to calculate error and accuracy rates. Understanding what causes degradation in performance is just as important as measuring it in the first place.
This page describes an open source CLI tool offered by Corti, providing a means for consistent, best practice speech to text evaluations.
Measure accuracy beyond simple metrics like Word Error Rate (WER)\
Identify failures on critical terms (e.g., medical vocabulary)\
Compare models, configurations, and prompts reliably\
Debug systematic errors and improve product quality
***
## A Better Way to Evaluate ASR
Metrics like WER treat all words equally, but in real-world use cases, not all errors carry the same weight. Missing filler words is very different from missing a diagnosis, medication, or key symptom.
**ErrorAlign** is a next-generation alignment and evaluation method designed for modern speech recognition.
Instead of forcing transcripts into rigid, one-to-one comparisons, it produces more natural, human-like mappings between reference and model output. This makes error analysis clearer, more reliable, and more actionable.
Produces more human-like transcript comparisons
Improves error attribution
Enables deeper, more actionable analysis
***
## Measure and Visualize Performance
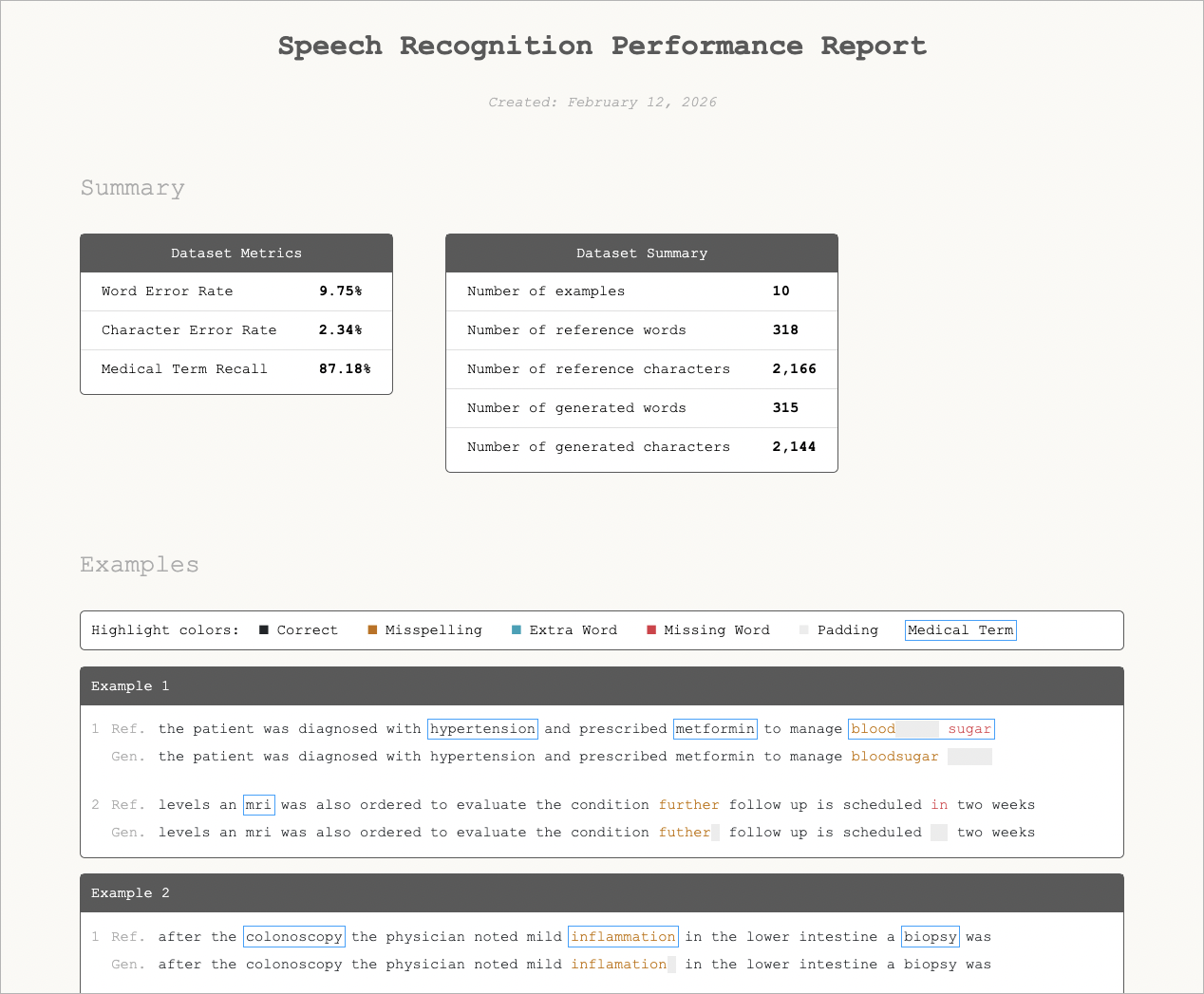
**Corti Canal** is an open source command-line tool that measures and visualizes speech-recognition performance.
Input a CSV with the expected reference transcripts alongside the model-generated output. A self-contained HTML report will be produced containing overall accuracy metrics and a word-by-word comparison, so you can see exactly where the model gets things right and where it does not.
* One to many files can be evaluated in a single run with metrics (e.g., word error rate, character error rate, and medical term recall) calculated across all rows in the CSV.
* Choose between standard Levenshtein distance or Corti’s [Error Align](https://arxiv.org/abs/2509.24478) algorithm for evaluation methodology.
* Medical terms are defined based on your preferences: reference a vocabulary library to be used in the evaluation, augment and maintain the vocabulary over time or customize for a given analysis.
* Analysis normalizes output (all lowercase, without punctuation) by default, but an option to disable normalization is available to include checking of casing and punctuation.
* In addition to the metrics, a visualization of the results is included, overlaying generated and final results to see each error and medical term identified in the results.
Built-in normalization
Advanced alignment methods
Visual error analysis
Domain-specific metrics (e.g., medical term recall)
***
## What This Enables
Instead of merely asking:
> “What is the WER?”
You can answer:
> “Where is my model failing, and does it matter?”
See some of our supporting research here:
* [Self-Supervised Speech Representation Learning: A Review](https://ieeexplore.ieee.org/abstract/document/9893562)
* [Do We Still Need Automatic Speech Recognition for Spoken Language Understanding](https://arxiv.org/abs/2111.14842)
* [Do End-to-End Speech Recognition Models Care About Context](https://arxiv.org/abs/2102.09928)
* Learn more at [corti.ai/research](https://corti.ai/research)